7. Linearna regresija
Iz Računalniška orodja v fiziki 2008 - 2009
| (One intermediate revision not shown) | |||
| Vrstica 32: | Vrstica 32: | ||
kjer je <tt>z[i]</tt> po vrsti <tt>1</tt>, <tt>x[i]</tt>, <tt>y[i]</tt>, <tt>x[i]*x[i]</tt> in <tt>x[i]*y[i]</tt>. To je druga, popolnejša oblika za najboljšo premico. V njej vsoto <math>S</math>, ki smo jo minimizirali, običajno označimo s <math>\chi^2</math> in jo lahko uporabljamo tudi za diagnozo kvalitete ujemanja. Za dobro ujemanje je njena pričakovana vrednost <math>m\pm\sqrt{2m}</math>. Govorimo o testu hi-kvadrat. | kjer je <tt>z[i]</tt> po vrsti <tt>1</tt>, <tt>x[i]</tt>, <tt>y[i]</tt>, <tt>x[i]*x[i]</tt> in <tt>x[i]*y[i]</tt>. To je druga, popolnejša oblika za najboljšo premico. V njej vsoto <math>S</math>, ki smo jo minimizirali, običajno označimo s <math>\chi^2</math> in jo lahko uporabljamo tudi za diagnozo kvalitete ujemanja. Za dobro ujemanje je njena pričakovana vrednost <math>m\pm\sqrt{2m}</math>. Govorimo o testu hi-kvadrat. | ||
| - | Mnoga računska orodja imajo že vgrajene ukaze za najboljše premice. Velja preveriti, katero od obeh oblik uporabljajo. | + | Mnoga računska orodja imajo že vgrajene ukaze za najboljše premice. Velja preveriti, katero od obeh oblik uporabljajo. Če imamo v datoteki v prvem, drugem in tretjem stolpcu vrednosti <math>x_i</math>, <math>y_i</math> in <math>\epsilon_i</math>, lahko najboljšo premico v '''Mathematici''' določimo in narišemo tako: |
| + | <tt> | ||
| + | Needs["LinearRegression`"] | ||
| + | Needs["ErrorBarPlots`"] | ||
| + | data = ReadList["podatki.txt", {Real, Real, Real}]; | ||
| + | <nowiki>fit = BestFit /.Regress[Map[{#[[1]], #[[2]]} &, data], {1, x}, x, Weights -> Map[1/(#[[3]])^2 &, data], RegressionReport -> BestFit]</nowiki> | ||
| + | p1 = ErrorListPlot[data]; | ||
| + | p2 = Plot[fit, {x, -1, 1}]; | ||
| + | Show[p1, p2] | ||
| + | </tt> | ||
| + | v '''gnuplotu''' pa: | ||
| + | <tt> | ||
| + | f(x)=k*x+n | ||
| + | fit f(x) "podatki.txt" using 1:2:3 via k,n | ||
| + | plot f(x) with lines, "hitrost.txt" with errorbars | ||
| + | </tt> | ||
== Naloge == | == Naloge == | ||
Current revision as of 10:56, 21. april 2009
Linearna zveza y = kx je najpreprostejša in najpogostejša zveza med dvema fizikalnima količinama, zlasti še, ker lahko tudi druge funkcijske odvisnosti v ozkem intervalu aproksimiramo z linearno zvezo: Δy = kΔx. Vemo, da sorazmernostni koeficient k za majhne Δx limitira k odvodu dy / dx.
Kadar moramo določiti koeficient v linearni zvezi dveh količin x in y, je s stališča merske tehnike koristno izmeriti več kot en par (x,y). Če določimo vrednosti yi, ki ustrezajo celi vrsti izbranih xi, i = 1, 2, ..., m, lahko z njimi določimo k z večjo natančnostjo. Obenem preverimo, ali linearna zveza zares velja, pa tudi, ali naša merska naprava dobro deluje v širšem intervalu spremenljivk. Zlasti se lahko zgodi, da ima merilec te ali druge količine premaknjeno ničlo. Tedaj se naša linearna zveza ne pokaže kot premica skozi izhodišče koordinatnega sistema, pač pa je nekoliko premaknjena. Zato velja, da iz vrste meritev xi, yi nikoli ne računamo koeficienta kot povprečje kvocientov yi / xi, pač pa vedno kot naklon premice, ki jo potegnemo skozi izmerjene točke.
Problem najboljše premice skozi dane merske točke je mogoče definirati na mnogo načinov, ki pa se vsi prevedejo na eno od dveh matematičnih oblik. Če smo za meritve že določili korelacijski koeficient (prim. 6.1-2), zadošča vedeti, da gre najboljša premica vedno skozi težišče oblaka točk (xpov,ypov) in da ima naklon Rσy / σx.
Sicer pa lahko koeficienta k in n najboljše premice y = kx + n določimo tudi z elementarnim računom. Zahtevamo, naj bo vsota kvadratov razdalj točk od premice najmanjša (načelo najmanjših kvadratov – least squares principle):
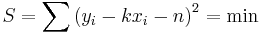 .
.
Sistem dveh enačb za k in n rešimo z naslednjim programom:
sum1 := 0; sumx := 0; sumy := 0; sumx2 := 0; sumxy := 0; for i:=1 to m do begin add(sum1, 1); add(sumx, x[i]); add(sumy, y[i]); add(sumx2, x[i]*x[i]); add(sumxy, x[i]*y[i]) end; k := (sum1*sumxy – sumx*sumy)/(sum1*sumx2 – sumx*sumx); n := (sumx2*sumy – sumx*sumxy)/(sum1*sumx2 – sumx*sumx)
V zaresni merilni tehniki se spodobi, da so meritve opremljene s statistično napako, torej 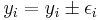 . Kadar se εi od izmerka do izmerka znatno spreminja, je teža posameznih točk različna. Statistično neoporečen rezultat dobimo, če v gornjem programu vse sumande utežimo z
. Kadar se εi od izmerka do izmerka znatno spreminja, je teža posameznih točk različna. Statistično neoporečen rezultat dobimo, če v gornjem programu vse sumande utežimo z 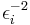 :
:
add(sumz, z[i]/sqr(ε[i]));
kjer je z[i] po vrsti 1, x[i], y[i], x[i]*x[i] in x[i]*y[i]. To je druga, popolnejša oblika za najboljšo premico. V njej vsoto S, ki smo jo minimizirali, običajno označimo s χ2 in jo lahko uporabljamo tudi za diagnozo kvalitete ujemanja. Za dobro ujemanje je njena pričakovana vrednost 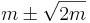 . Govorimo o testu hi-kvadrat.
. Govorimo o testu hi-kvadrat.
Mnoga računska orodja imajo že vgrajene ukaze za najboljše premice. Velja preveriti, katero od obeh oblik uporabljajo. Če imamo v datoteki v prvem, drugem in tretjem stolpcu vrednosti xi, yi in εi, lahko najboljšo premico v Mathematici določimo in narišemo tako:
Needs["LinearRegression`"]
Needs["ErrorBarPlots`"]
data = ReadList["podatki.txt", {Real, Real, Real}];
fit = BestFit /.Regress[Map[{#[[1]], #[[2]]} &, data], {1, x}, x, Weights -> Map[1/(#[[3]])^2 &, data], RegressionReport -> BestFit]
p1 = ErrorListPlot[data];
p2 = Plot[fit, {x, -1, 1}];
Show[p1, p2]
v gnuplotu pa:
f(x)=k*x+n fit f(x) "podatki.txt" using 1:2:3 via k,n plot f(x) with lines, "hitrost.txt" with errorbars
Naloge
- Za meritve[1] v datoteki "HitrostTokaOdFrekvence.txt" (naloga 6.1) določi parametra najboljše premice. Ker so podane napake hitrosti, lahko določiš tudi χ2.
- Skozi oblak podatkov "Tintin.dat" potegni najboljšo premico. Uporabiš lahko kar korelacijske rezultate iz naloge 6.2.
- Skozi točke v histogramu podatkov "Interval.dat" poskusi potegniti najboljšo eksponentno funkcijo w = Ae − λx, ki jo moramo najprej predelati v linearno zvezo. Z logaritmiranjem dobimo ln(w) = ln(A) − λx. V grafu y = ln(w) od x sta koeficienta premice k = − λ in n = ln(A). Po teoriji verjetnosti mora biti koeficient λ enak recipročni povprečni vrednosti histograma.
- Teorija kemijske kinetike napove za sigmoidno krivuljo iz podatkov "Adrenalin.dat" (naloga 1.1) naslednjo odvisnost F / Fmax = c / (a + c), kjer pomeni a koncentracijo s polovičnim maksimalnim učinkom. Določi koeficienta Fmax in a. Pretvori v linearno zvezo – ena pot je uvedba recipročnih spremenljivk 1 / F in 1 / c, druga pa je uvedba spremenljivke c / F.
Literatura
- ↑ Blaž Kavčič, Dušan Babič in Igor Poberaj, Mikrofluidično vezje z mikročrpalko, OMF 56 (2009) 1.